作者:请叫我浪漫先生_858 | 来源:互联网 | 2023-07-23 17:59
篇首语:本文由编程笔记#小编为大家整理,主要介绍了湖仓一体数据平台架构相关的知识,希望对你有一定的参考价值。
随着数字化技术的更新迭代,数据库、数据仓库、数据湖等各种概念层出不穷,MPP数据库、Hadoop、对象存储、Hudi等各种数据技术不断涌现,湖仓一体概念逐步被人们所关注,在国际知名机构Gartner发布的《Hype Cycle for Data Management 2021》中,湖仓一体被正式纳入到技术成熟度曲线中。最近有很多朋友都在讲湖仓一体架构,那究竟什么是湖仓一体?本期金子就和大家聊聊湖仓一体的数据平台架构!
01 数据湖与数据仓库
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据存储系统,它主要存储的是结构化数据,历史数据通过抽取、转换、整合以及清理,并导入到目标表中,主要用于业务决策分析。
随着当前大量信息化发展和电子设备产品普及,产生大量的照片、视频、文档等非结构化数据,人们也想通过大数据技术找到这些数据的关系,所以设计了一个比数据仓库还要大的系统,可以把非结构化和结构化数据共同存储和做一些处理,这个系统叫做数据湖。
数据湖是一个以原始格式存储数据的存储库或系统,它按原样存储数据,而无需事先对数据进行结构化处理,可以存储结构化数据(如关系型数据库中的表),半结构化数据(如CSV、日志、XML、JSON),非结构化数据(如电子邮件、文档、PDF)和二进制数据(如图片、音频、视频),以供机器学习、深度学习、统计分析等多种形式数据分析应用。
数据湖开放的数据存储结构给数据入湖带来了更大的灵活性,各种结构化、半结构化、非结构化的原始数据可以直接入湖。另外,开放存储给上层的计算引擎也带来了更多的灵活度,各种计算引擎需要遵循相当宽松的兼容性约定即可根据自己针对的场景随意读写数据湖中的数据。而数据仓库则更关注数据使用效率、数据的安全性和数据治理能力,这对企业的长远的成长性发展至关重要。
02 湖仓一体概念
湖仓一体是一种新型开放式架构,将数据湖和数据仓库的优势充分结合,它构建在数据湖低成本的数据存储架构之上,又继承了数据仓库的数据处理和管理功能。湖仓一体打通数据湖和数据仓库两套体系,让数据和计算在湖和仓之间自由流动,更能发挥出数据湖的灵活性,以及数据数据仓库的成长性。
但是湖仓一体≠数据湖+数据仓库,湖仓一体不等同于数据湖和数据仓简单打通,湖仓一体的构建需要解决以下三个关键问题:
-
湖和仓的数据/元数据在不需要用户人工干预的情况下,可以无缝打通、自由顺畅地流动;
-
系统根据特定的规则自动地将数据在湖仓之间进行缓存和移动,根据规则自动决定哪些数据放在数仓,哪些保留在数据湖,进而形成一体化;
-
湖和仓有统一的开发体验,存储在不同系统的数据,可以通过一个统一的开发/管理平台操作。
03 湖仓一体平台架构
基于开源生态的主流湖仓一体解决方案采用存储计算分离的架构,对象存储(OSS/S3/MinIO等)和Hadoop HDFS提供支持Apache hudi、Apache Iceberg等数据湖的数据存储机制,并通过Flink、Spark、Trino(原Presto)三个不同引擎进行相关数据处理和交互式查询,对外提供不同类型的服务。湖仓一体具体平台架构如下:
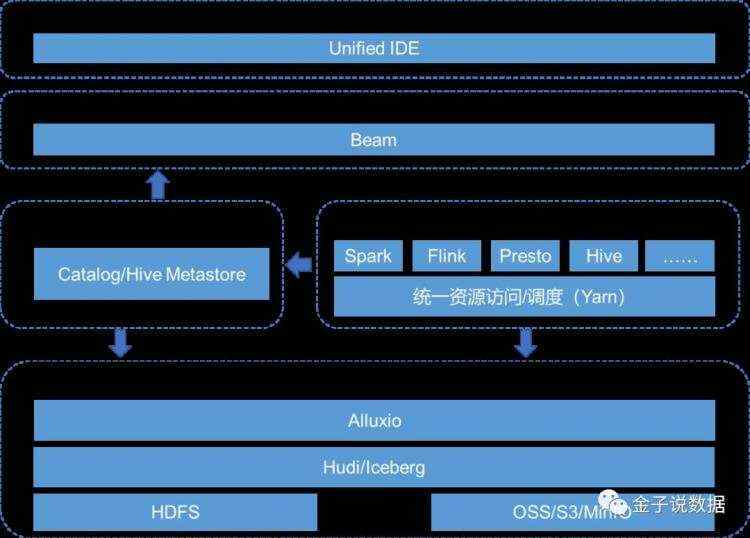
数据存储
数据存储支持OSS/S3/MinIO等对象存储和Hadoop HDFS,对象存储存储非结构化、原始数据、冷数据,提供高性价比,HDFS存储结构化数据,提供高性能存储。
使用Hudi/Iceberg作为数据存储中间层,能够基于HDFS、对象存储等底层存储,支持ACID语义、实现快速更新能力。
通过Alluxio进行数据缓存,加速Spark、Flink、Trino(原Presto)等计算引擎对数据湖的读写。
计算引擎
计算支持多引擎,Spark、Trino、Flink等均实现serverless化,跑在Kubernetes中,即开即用,满足不同查询场景,并通过Yarn进行统一资源访问/调度。
智能元数据
基于特定的规则,智能识别结构化、半结构化文件的元数据,构建数据目录,并转化成内置存储中的一个Hive表,统一进行元数据管理,提供类HiveMeta API针对不同计算引擎访问底层数据。
统一编程模型
Apache Beam作为统一的编程模型,提供统一的IDE,统一流和批,抽象出统一的API接口,并且生成的数据处理任务应该能够在各个计算引擎上执行,使得用户可以自由切换数据处理任务的执行引擎与执行环境。

金子说数据
聊聊数据技术,谈谈数据业务
8篇原创内容
公众号







 京公网安备 11010802041100号
京公网安备 11010802041100号